 |
Annie E. Mitchell (1884-1938) |
Good day all. This is Stephen D Handy Jr. I would like to welcome everyone to this document, which purpose is to reveal a big discovery I made in my shared family tree about an important ancestor of mine – Ms. Annie Elizabeth Mitchell-Proctor (1884-1938). To be more accurate, I am going to reveal the actual paternal ancestry, (or the father to be more specific), of Ms. Annie Mitchell, who is my maternal great-grandmother.
This discovery was made during my routine DNA genealogical analysis of DNA data which was gathered over the years from various maternal relatives of mine.
The roadmap of this document will first start off with the new discovery that has been substantiated as fact. Second, we will reexamine the initial belief concerning Ms. Mitchell’s paternal ancestry in detail. Third, we will move to examine the recent new observations and evidence from DNA Genealogy. Fourth, we will then wrap it up, by meeting some new relatives, whom would be our new 1st through 2nd cousins, who have helped me uncover this discovery 😊.
With that said, let’s begin with a discovery that I recently made for which this entire document is about.
DISCOVERY: The father of Annie Elizabeth Mitchell (1884-1938) was not Bolton Herbert Mitchell Sr (1868-1944). The biological father of Annie Mitchell appears to have been Louis Henry Zehnder Jr (1865-1911)
Of course, this is a pretty big change in the Mitchell family tree!!!!! The implication of this is that Annie Elizabeth was not a Mitchell but a Zehnder. Please believe me when I say that I was initially shocked myself. However, we are always reminded that a written record is only as good as the person that supplies that record. As we will see, the Zehnder family originated in and are from Switzerland. Along with the new discovery concerning the paternal ancestry of Annie Mitchell, I also made a few other discoveries which I will highlight as well.
Let’s begin with a review of an important family member to put everything into proper perspective: Ms. Sarah Wright.
Sarah “Missie” Wright (1867-1918)
The starting point of our entire discussion is Ms. Sarah Wright. Sarah Wright would be a 2nd great grandmother to me and a great grandmother to others that are reading this document. Sarah was born in Rankin County, Mississippi in May of 1867. Sarah was one of five girls born to parents, Joe Wright (1830-?) and Celia Cook (1830 -?). The earliest Sarah appears is in the 1870 Census record in Township 4, Rankin, Mississippi. At some point between 1870 and 1880, Sarah and her siblings, along with their mother Celia, migrated to Jackson, Mississippi in Hinds County.
In the 1880 Census, Sarah appears with her mom Celia and her
sister Alice. Sarah is listed as 13 yrs old, and she is listed as a student. When
we arrive at the 1900 Census, we see our 1st piece of evidence.
 |
1900 Census In Jackson Mississippi |

DNA Genealogy: The Basics
Before diving into the DNA data numbers, let’s first understand some basic concepts, so the DNA data makes sense. The main DNA test that presents the evidence is called an autosomal DNA test. The DNA testing companies known as Family Tree DNA and Ancestry.com, name their autosomal DNA tests both the Family Finder and AncestryDNA tests.

Humans have 46 chromosomes. Chromosomes numbered 1 through 44 are the autosome chromosomes. You get 22 autosomes from mom and the other 22 autosomes come from dad. An autosomal DNA test such as Family Finder or AncestryDNA, looks at shared DNA segments that you and another person have in common. Those shared DNA segments are inherited from a shared recent common ancestor.
The centimorgan is the amount of shared DNA between any two individuals. The centimorgan is in units known as cMs. There is a characteristic range of centimorgans that is present within two known close relationships:
- Parent – Child: 3400 cMs to 3800 cMs
- Full Siblings: 2500 cMs to 2800 cMs
Here are some examples shown below in embedded photos below:

The photo above is from Family Finder (from my DNA kit) where I
tested myself and my parents. The centimorgan numbers fall in range of a parent
– child relationship. Here is another example from two full siblings:

The above photo is a DNA match in my mother’s
DNA profile. The match is her full sibling – Richard Mitchell. The
shared DNA is 2641 cMs between the two of them. The number of 2641 cMs is a typical
centimorgan count associated between two full siblings.
However, once we look at relationships below full siblings, we see multiple relationships that fall within a range of centimorgans. For example, look at this photo below from my DNA profile at Family Tree DNA.

Shown in the above photo, is my maternal uncle, Richard Mitchell and my paternal grandmother, Juliette Turner-Handy, within my Family Tree DNA profile, who are DNA matching me. As you can see, both of their respective cM numbers are close: 1920cM and 1891cM. Here is a 2nd example.

Shown above are two relatives of mine within my DNA profile. The 1st
relative is my dad’s first cousin, Rita Moore, who is sharing 328cMs of DNA
with me. The 2nd relative is my maternal grandmother’s brother, John W
Ridgeway Jr, who is sharing 319 cM of DNA with me. As one can see, those two
numbers of 328 cM and 319 cM are very close!!!!

Notice in the above centimorgan table that the word “half” appears quite frequently in the table. The word “half” is a term used to refer to a relationship between two people who share a single common ancestor and not a pair of common ancestors. Here is why this is important to understand. Most of the people whom you match in an autosomal DNA test like Family Finder or AncestryDNA, are going to be cousin relationships.
For example, in Family Finder, I have 2384 matches. Most of those 2384 matches are going to be cousin relationships. Here is an important principle to remember moving forward.
PRINCIPLE: All cousin relationships begin with two siblings at some point in the past. If the two past siblings share BOTH parents, then they are
FULL siblings. If the two past siblings share ONE parent, then they are HALF
siblings. As we will see, this is reflected in a shared cM count as well.
Since full siblings share two parents, full siblings will share twice as more centimorgans of DNA (2400 cM – 2800 cM). A pair of half siblings will share (1400 cM to 1900 cM).
The term “phased” is also used to
refer to half siblings as well. A “phased” relationship implies that a single
common ancestor is shared as opposed to a pair of shared common
ancestors. Let’s see a few examples below.
{kind=link}
{kind=link}

Shown above is my dad’s first cousin – Ms. Laurie Handy within my dad's DNA kit. Both Laurie and Steve Sr’s fathers (Clarence Handy and William E. Handy) were full siblings sharing two parents. We see 792 cMs of shared DNA between Laurie and Steve Sr. Here is another example of two 1st cousins.

Shown above is my mom’s first cousin, Ms. Lonette Lanier, from my mom's DNA kit at FTDNA. Both my mother and Lonette’s parents, (Ulysses Mitchell and Nancy Proctor), were half siblings, sharing the same mother – Annie Elizabeth Mitchell-Proctor. We see 440 cMs of shared DNA between Mel Mitchell and Lonette Lanier.
As we can see, 440 cMs of DNA is smaller when compared to the 792 cMs of DNA shared between my dad and his 1st cousin, Laurie Handy. However, it is understandable, given that Mel Mitchell and Lonette Lanier both have a “phased” relationship between themselves.
In addition, any DNA matches in the Family Finder or AncestryDNA test, that are in common between Mel and Lonette, means those DNA matches are related through the shared common ancestor of Mel and Lonette, which would be their grandmother, Annie Mitchell-Proctor. This is a neat little trick that can be used in DNA Genealogy when comparing phased relationships. The trick is called triangulation.
Now that you understand the science behind DNA Genealogy, we can now begin with some initial observations I encountered on AncestryDNA and FTDNA. Since we were just talking about full siblings, let’s look at two full sisters, Ms. Amy Zehnder and her sister, Ms. Lee Zehnder-Ross. Amy and Lee Zehnder both are common DNA matches to myself, to my mom Muriel Mitchell, to our cousin Lonette Lanier, and to our cousin Ms. Gwen Taylor.
1st Observation: Amy & Lee Zehnder


The observation that really is an eye catcher is the fact that both sisters are DNA matching to my cousin Lonette Lanier and to my mother Mel Mitchell!!!! Remember that Lonette and Mel form a phased relationship with each other. This automatically means that Amy and Lee are related through Annie Mitchell-Proctor (1884–1938).
Take a look at the image below showing Lee Zehnder's DNA matches. Notice the high DNA amount of 246 cMs shared with Richard Mitchell. A cM count of 246 cM indicates a relationship within the 2nd cousin range. In fact, 246 cMs of DNA is consistent with an exact phased 2nd cousin relationship and is a quite high amount on record.

2nd Observation: Zehnder Tree
The 2nd set of observations came from a posted tree of the Zehnder Family which was uploaded by Amy Zehnder. Amy has constructed a nice family tree of her immediate ancestors on AncestryDNA. Shown below is part of her tree:

When I eventually went through Amy Zehnder’s tree, I made a big discovery. Remember that the Zehnder family origin is in Switzerland. Amy’s 2nd great grandfather was Louis Sebastian Zehnder Sr, who was born in Einsiedeln, Switzerland in 1826. The big discovery was that Louis Zehnder Sr came and settled within the United States in Jackson, Mississippi in 1853.

Jackson Mississippi is where
my mom’s father and my mom’s paternal uncles-aunts are from!!!! Thus, it was
quite apparent that a Zehnder must be an ancestor of mine which explains why my
family shares significant cM amounts of DNA with Amy and Lee Zehnder. Remember,
that it is through Annie Mitchell-Proctor (1884-1938), that the Zehnder
ancestor connection originates.
Annie Mitchell’s maternal
ancestry is from her mother, Sarah Wright (1867-1918). The Wright family stems
from Rankin County, Mississippi. There were no apparent direct ties to the Zehnder
family within the Wright family lines within Rankin County, MS. Equally important, we already know the parents of Sarah Wright. Therefore, the Zehnder connection must have come through
Annie Mitchell’s paternal side.
Traditionally, on paper, it
was stated that Annie E. Mitchell’s father was Bolton Herbert Mitchell Sr
(1868-1944). This is what was submitted and shown on Ann Mitchell’s death
certificate. Thus, the initial hypothesis or guess from me, was that Louis
Sebastian Zehnder (1828-1871) must have fathered Bolton H Mitchell Sr
(1868-1944). Let’s see if that is true.
Bolton Herbert Mitchell Sr (1868-1944)
Bolton Herbert Mitchell Sr was born in Forest, Mississippi in 1868. I initially assumed that Bolton Mitchell Sr was my 2nd great grandfather. Bolton Mitchell Sr’s mother was a woman named Millie Green (1850-1920). Millie Green was born in Selma, Alabama. Thus, Millie Green would be a 3rd great grandmother to me. Millie Green produced a daughter named Carrie Mitchell (1876-1937) in Forest, Mississippi as well. Millie Green and her children first appear in the 1880’s census in Jackson, MS. Bolton Sr also appears the 1900 and 1910 census records, along with his mother. The interesting observation is that Bolton Mitchell Sr is listed as mulatto in two census records:


The term, “mulatto”, in social circles generally refers to
someone whose father is white, and whose mother is usually black, in ethnic
terms. Thus, I was more confident that Louis Sebastian Zehnder fathered Bolton
H Mitchell Sr.
However, the
evidence so far would only be circumstantial at best. It would be nice if I
could get DNA results from either a child or grandchild of Bolton H Mitchell Sr
to confirm or disprove a connection to Louis S Zehnder Sr (1828 -1871). The
Y-DNA test, which is only for men, would be the perfect DNA test to prove a
paternal connection.
Bolton Mitchell Sr did have a son
with Sarah Wright who was Bolton Herbert Mitchell Jr (1890-1954), but he is
deceased. However, Bolton Mitchell Jr’s sons are quite alive and kicking in
Mississippi and California!!!!!! That’s where Mr. Edward C. Mitchell Sr (1948) comes
in. However, when Edward Mitchell’s DNA results came in, I got a big surprise!!!!!
Edward Charles Mitchell Sr

Shown to your right is Mr. Edward Charles Mitchell Sr. Edward is the grandson of Bolton H Mitchell Sr (1868-1944). Edward’s dad was Bolton H Mitchell Jr (1890-1954). In other words, Edward’s aunt was Annie Mitchell-Proctor. Thus, Edward Mitchell would be a 1st cousin to Ulysses Mitchell, Nancy Proctor-Lanier, and Earl Reynolds.
Remember, that it was assumed
that Bolton H Mitchell Sr and Sarah Wright produced three children: Annie E
Mitchell (1884-1938), Bolton H Mitchell Jr (1890-1953), and Carrie Mitchell
(1893-1973). Therefore, it’s assumed that all three siblings were full siblings
and Edward’s DNA results would reflect a full sibling relationship. However, a
completely different result was produced from Edward Mitchell’s DNA results!!!!!!
As you can see from the above DNA results, these are low centimorgan numbers, much too low for a full cousin relationship. For example, Edward Mitchell and Lonette Lanier share only 223 cMs of DNA. For a 1st cousin once removed relationship that stems from two full siblings, we should see numbers in the range of 400 cMs to 500 cMs. Let's use the cM count between Richard Mitchell (my uncle) and Edward Mitchell Sr which is 108cM. If we double 108 cMs to 216 cMs, we still come nowhere near close to a full cM range of 400 cMs to 500 cMs.
Therefore, the two siblings in
question: Bolton H Mitchell Jr (1890-1945) and Annie Elizabeth Mitchell-Proctor
(1884-1938) were half siblings sharing one ancestor, the same mother Sarah
“Missie” Wright (1867-1918), but different fathers!!!!! Furthermore, Edward
Mitchell is not DNA matching to either Amy Zehnder, Lee Zehnder-Ross, nor to any
of the Zehnder relatives we see matching my mom Mel, Lonette Lanier, and Gwen
Taylor.
Now let’s look at one final DNA test that Edward Mitchell took, a Y-DNA test.
Y-DNA Test




The results show no Y-DNA match at all!!!!!!!! Neither Jacob Zehnder nor Edward Mitchell Sr appear in either others Y-DNA results. Thus, we have a final definitive piece of evidence showing that Bolton H Mitchell Sr (1868-1944) is NOT an ancestor nor a relative of me, nor any of my maternal family members. Therefore, who was Annie E Mitchell’s father?
Summary Of DNA Evidence🧬
 |
| Bolton Mitchell Jr (1890-1954) |
At this point, let's take a step back and review the evidence presented to everyone. From the autosomal DNA data of current descendants, we see that the original siblings: Annie E Mitchell (1884-1938) and Bolton H. Mitchell Jr (1890-1954) were half siblings, sharing a single parent – Ms. Sarah Wright (1867-1918). In other words, the father of my ancestor, Annie E Mitchell, was not Bolton H Mitchell Sr (1868-1946). The autosomal DNA evidence, along with concrete documents, clearly points to Louis Sebastian Zehnder Sr (1828-1871) as an ancestor to Annie E Mitchell. But was Louis Sebastian Zehnder Sr the father of Ann Mitchell?
In review, the Y-DNA evidence from Edward Mitchell Sr, a grandchild of Bolton H Mitchell Sr, completely takes out Bolton H Mitchell Sr out of the Zehnder picture. Moreover, Louis Sebastian Zehnder Sr simply died before Annie Mitchell was born in 1884. Therefore, Louis Sebastian Zehnder Sr (1828-1871) could not have fathered Annie E Mitchell (1884-1938) based alone on the dates. Thus, the only possible conclusion left is that one of Louis Zehnder Sr’s sons must have fathered Annie E. Mitchell in the years between 1883-1884.
There is a clever DNA genealogical “technique” that we can do to help confirm if one of the children (sons) of Louis Sebastian Zehnder Sr is the father of Annie Mitchell. The technique goes like this. Let’s see if there is evidence of autosomal DNA input from not only from Louis Sebastian Zehnder Sr, but also from his spouse, Rosina Mohr (1828-1898). If a son of Louis Sebastian Zehnder Sr and Rosina Mohr (1828-1898) fathered Annie Mitchell, then we should see "DNA fingerprints" from both Zehnder Sr and Mohr, within Annie Mitchell's modern descendants such as myself.
Let’s check AncestryDNA to see if my mom has any autosomal DNA matches with the last name of Mohr. Voila!!!!! We have a Mohr match. Please see the below picture.

The above photo shows Mr. Gary Mohr as a DNA match to my
mom. Gary Mohr is sharing 13 cMs of autosomal DNA with my mom. This means Mr.
Gary Mohr and my mom share a recent common ancestor. But is not enough to
simply have the surname of Mohr. The key question to answer is this: Is there
any direct evidence that connects Mr Gary Mohr to my presumed ancestor, Mrs.
Rosina Mohr-Zehnder? The answer to that question is a resounding yes!!!!! Let’s
look and see!!!!!!!!!
Rosina Mohr-Zehnder (1828-1898)
Rosina Mohr (1828-1898) was born in Bavaria, Germany in
1828. Given the time of history, it should be no surprise that Ms Mohr would
arrive upon the shores of the US in a ship. It appears that Rosina Mohr arrived
on a ship called the Mayflower, which docked in New Orleans, LA in 1848.
 |
| Arrival Of Rosina Mohr On Mayflower Ship To New Orleans in 1848 |

By 1850, Rosina Mohr appears in the 1850 Census in New Orleans,
LA. Rosina Mohr is staying with a family of Mohr’s, and she is 18 yrs old. Charles
Christian Mohr (age 37) and his wife Mary Ann Schaetle (age 27) are parents to three children: Rosalie, Charles, and George William. It is unknown if Rosina
Mohr is related to the family until now!!!! If you remember Mr. Gary Mohr, who
matched my mom (Muriel) with 13 cMs of DNA shown above, is descended from George William
Mohr (1848-1882). This is seen in the photo below from Chelsea Mohr, who is the
daughter of Gary Mohr.
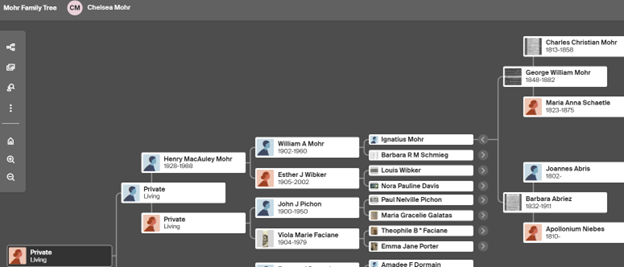
Thus, we have concrete evidence of my family’s connection
to the Mohr family. This piece of evidence firmly places my great grandmother
Annie Mitchell-Proctor (1884-1938) as being fathered by a child (son) of Louis
Sebastian Zehnder Sr (1828-1871) and Rosina Mohr as their DNA fingerprints are well
within me and my family. But which child (son) is the father of Annie E.
Mitchell-Proctor (1828-1938)? Let’s finally find out!!!!!!!!!!!!
Louis Henry Zehnder Jr (1865-1911)
Rosina Mohr eventually met and married a gentleman named Antonius Nahrgang (1821-1855) on May 30th, 1854. Mr Nahrgang died a year later in 1855 and thus Rosina Mohr moved on. On April 26th, 1858, Rosina Mohr-Nahrgang married her 2nd and final spouse, Louis Sebastian Zehnder Sr. Together, both Rosina and Louis Sebastian Zehnder had five children that lived to adulthood:
1) Emma Zehnder (1860-1898)
2) Albert Zehnder (1864-1937)
3) Louis Henry Zehnder Jr (1865-1911)
4) Charles Zehnder (1867-?)
5) George Zehnder (1871-?)
So now let’s answer the question to which this whole entire
document has been about. Which one of the four sons above fathered Annie Elizabeth
Mitchell (1884-1938)? The answer lies within the centimorgan count numbers. The
descendants where we see the largest shared cM numbers reveal the ancestor in
question. Fortunately, in this case, we see shared cM numbers that can be seen
as record high!!!! And those high cM numbers appear to stem from the
descendants of Louis Henry Zehnder Jr. To be transparent, we don’t have any shared
cM numbers from the descendants of Charles, George, nor Albert Zehnder to
compare against.
However, the shared cM numbers from the known descendants
of Louis Henry Zehnder Jr, (at least one example), are so high that no doubt is
left. For example, shown below is the shared cM between my full 2nd
cousin Tei’Anne Cash and myself.



We see 178 cMs of shared DNA and 132 cMs of shared DNA with
Maurice Jackson and Sharon Cobb respectively. Now let’s look at my uncle
Richard Mitchell-Ridgeway compared to Amy, Jacob, and Lee Zehnder.

From the above photo, you can see that Richard
Mitchell-Ridgeway shares 246 cMs of with his phased 2nd cousin Ms Lee
Zehnder. 246 cMs of DNA for a phased 2nd cousin is relatively
high!!!!! These cM numbers shown above are simply consistent with phased 2nd
cousins. With cM numbers such as these, it leaves no doubt of whom the ancestor
and father of Annie E Mitchell-Proctor is in this case – Louis Henry Zehnder Jr
(1865-1911).
Let’s examine one more final example to bring this home.
Please see the below photo.


Sah_Chopper is descended from Emma Zehnder-Muller (1860-1898) through her grandfather, Otto Muller (1898-1980). Emma Zehnder was the daughter of Louis Sebastian Zehnder Sr (1828-1871) and Rosina Mohr (1828-1898). Emma was also the sister of Louis Henry Zehnder Jr (1865-1911). Even though Emma was a female and certainly could NOT have fathered Annie Mitchell-Proctor (1884-1938), the point still is valid. That point being that we see high and consistent levels of shared cM DNA amounts as stemming from the descendants of Louis Henry Zehnder (1865-1911).
Louis Henry Zehnder Jr (1865-911) is clearly the father of Annie Elizabeth Mitchell-Proctor (1884-1938). Given the high levels of shared DNA (cMs) with Louis Henry’s descendants such as Amy, Lee, and Jacob this leaves Louis Henry Zehnder Jr, as the father without a doubt.
Final Facts And Thoughts
According to my cousin Amy Zehnder, the Zehnder’s in Jackson, Mississippi owned a hotel. The
census records also show Louis Henry Zehnder Jr as a merchant in the 1900
census records. There is also a newspaper article from 1899, showing Louis
Henry Zehnder Jr was a proprietor as well.

In 1895, Louis H Zehnder Jr
married Annie Fragiacomo. There is a newspaper clipping posted below detailing
the marriage. At the age of 15, Sarah Wright was pregnant with Annie Mitchell,
by Louis H Zehnder Jr. I am guessing that Sarah Wright didn’t want the news of
her pregnancy, by Louis H Zehnder Jr, to hit the newspapers back then. Given the
social environment back then, who could blame her.
Well, that’s it!!!!!!!!!!! I hope this document has been informative. As additional
information, I have posted some newspaper clippings. It seems my ancestor, Mrs.
Annie E. Mitchell-Proctor, was quite known in Jackson, Mississippi. Below is a newspaper
article about the passing of Annie Mitchell-Proctor in 1938.
Take Care!!!!!!!!
 |
| (Newspaper Clipping Of Annie Mitchell-Proctor in 1938) |

